こんにちは!
前回の「統計学 その7」では母集団と標本集団、ヒストグラムの面積と確率という、確率分布等の話をしたかと思います。
それでは、本格的に「手元にあるデータを眺めるだけでなく、限られたデータから全体で起きる確率を推測する」ということをやってみようと思います。
今回は「正規分布」「線形変換」「標準化」について学んでみましょう。
1. 正規分布とは?
正規分布とは、ヒストグラムの階級の幅を短くしていくと得られる「滑らかな」ヒストグラムです。「統計学 その5」でも存在だけは出てきていましたがその時の説明としては「平均値の付近にデータが多く集まっている図形」という簡単な説明だけでした。
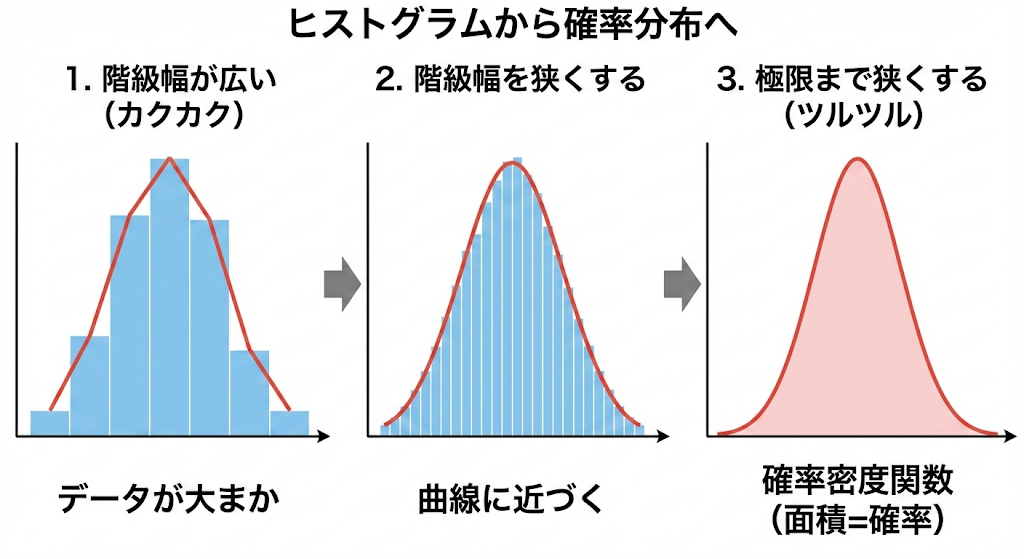
上記の図が、ヒストグラムと正規分布の違いになります。「統計学 その3」で学習した通り、合計の度数が少ないと、階級値を細かく分けてもほとんど意味がない図になってしまうという話をしたかと思います。しかし、裏を返せば調査するデータ数が多いほどヒストグラムは正規分布の形に近づいていくと考えられると思いませんか?
そのような、法則性のある数学的な関数の曲線にヒストグラムを見立てたものが「正規分布」なのです。
しかし、限られたデータではヒストグラムのようなギザギザな形にしかならずに、正規分布のようなツルツルな形になるとは限りません。しかし、複数回データをとって計算し続けると、必ず正規分布になることが数学的には約束されており、その定理を「中心極限定理」と言います。(中心極限定理は大学で数学をやっていないと表記が難しく証明を読むことが難しいためここでは割愛します。いつか数学ガチ勢の為の記事も執筆します。)
1-1. 数学Ⅲでネイピア数eを学んだ方向け
先ほど、正規分布を数学的な関数の曲線と言いましたが、確率密度関数を関数として記述すると以下のように書くことができます。
ここでは、を標準偏差、を平均値とします。
この関数をの範囲で積分することにより、その事象がa以上b以下を取る確率を求めることができます。これを数式として表すと以下のように記述できます。
グラフを書いて積分範囲の面積を図示すると以下のようになります。
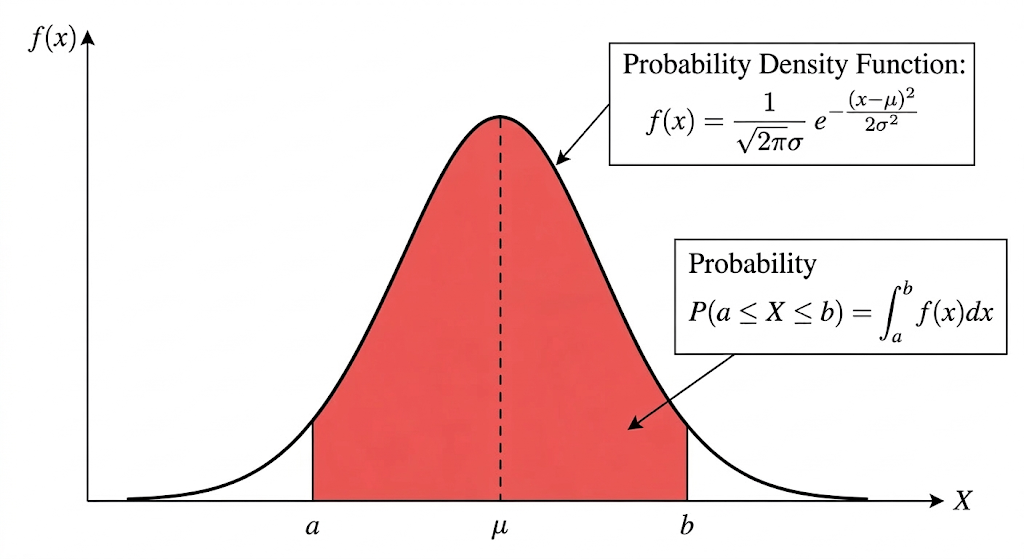
上記の図からもわかるように、ヒストグラムを確率密度関数に置き換えてみているので、面積がそのままある範囲の値を取りうる確率であることが理解できるかと思います。
さらに、として積分すると
このように、正規分布の確率密度関数を平均から標準偏差分ずらして積分すると、この間に値が入る確率は「約68%」とわかります。このように、平均から標準偏差1つ分のずれの範囲に値が入る確率は68%程度であると数式から算出できることが確認できたかと思います。(リクエストがあれば私の手書き計算でどのように積分するかを載せます)
興味がある方はの範囲で積分してみると、確率が「約95%」であることも確認してみてください。
2. 線形変換
正規分布を考えるときに、元のデータをそのまま見ると本質的な部分が見えにくい場合があります。そこでデータを見やすい形に変換しデータに解釈を与えることがよくあります。その作業の一つを「線形変換」といいます。
あるn個のデータ群があったとします。
i番目のデータを見たときに以下の変換を行います。
ここではa,bを互いに定数とします。
このようにしてできたデータ群は、変換元のデータをすべてa倍してからb足しているだけの単純な変換になっているので、元のデータ群の平均値を、分散をとしておくと、変形後のデータ群は以下のように表すことができます。
上記の式のように変換することができます。
2-1. 線形変換する理由
一見、何の意味もないように見える線形変換ですが、満点が10点のテストと、満点が200点のテストの平均点や分散を比較することを考えてみます。
満点が10点のテストでは、受けてる人のレベルに関係なく平均点は10点までしかとることができません。しかし、満点が200点のテストでは平均点として10点以上になることが容易に考えられます。この二つのテスト結果を比較して平均点は「満点が10点のテストを受けているクラスは平均点が低いので、満点が200点のテストを受けているクラスの方が優秀」と言い出したら、明らかに不当な評価を受けていることがわかるかと思います。
このように単純に比較しにくい、2つのテストの結果を比べたい場合には「線形変換」を行うことで、基準をそろえ比較しやすい形に変換することができます。
3. 標準化とは?
線形変換の中でも、特に統計学で重要なものを標準化といいます。
標準化とは、データの平均値を0、標準偏差を1にそろえるように変換することです。
この変換を行うことで、もともとの単位や尺度が異なるデータでも、同じ基準で比較できるようになります。
あるデータ の平均値を 、標準偏差を とすると、標準化した値 は次の式で表されます。
この を標準得点やz値といいます。
標準化とは、もとのデータの「平均との差」が「標準偏差何個分であるか」を確認しやすくした作業といえます。つまり線形変換とは、の値がどれくらいの大きさであるのかを見ているわけでは無く、「その値が集団の中でどのあたりに位置しているのか」を確認しやすくした線形変換ということができます。例えばとあらわせる値をとるは標準偏差一つ分だけ平均より大きい値といえます。
4.最後に
ここでは「正規分布」「線形変換」「標準化」この3つの概要をお話しました。次はこれらを利用した、z値の求め方と「標準正規分布表」を利用して、どの程度その値が起こりやすいかを計算する演習問題を解説しようと思います。

コメント